
โดย: falcon_mach_v
เมื่อช่วงปลายปีที่ผ่านมา มีข่าวเล็กๆ ข่าวหนึ่งที่อาจไม่ได้เป็นที่สนใจของคนในวงกว้างมากนักนั่นคือ Apple ประกาศเข้าซื้อกิจการ Topsy บริษัทวิเคราะห์ข้อมูลใน Twitter ซึ่งใช้วิธีการดึงข้อความในทวีตจำนวนมากมาเก็บไว้ก่อนที่จะค้นหาและวิเคราะห์ข้อมูลต่อไป นักวิเคราะห์หลายรายคาดว่า Apple ต้องการเทคโนโลยีของบริษัทดังกล่าวเพื่อนำไปพัฒนาปรับปรุงระบบการแนะนำเมื่อผู้ใช้ทำการค้นหาใน iTunes และ App Store เพื่อให้ได้ผลการค้นหาที่ตรงความต้องการมากขึ้น
หลายคนอาจเกาหัวพร้อมกับตั้งคำถามถึงความคุ้มค่าของการทุ่มเงิน 200 ล้านเหรียญสหรัฐ ไปกับบริษัทที่บุคคลนอกวงการน้อยคนมักจะรู้จัก แต่เชื่อหรือไม่ครับว่าร้านค้าออนไลน์ iTunes และ App Store นั้นสามารถทำเงินให้กับ Apple ได้มากกว่าหนึ่งหมื่นล้านเหรียญต่อปี ซึ่งมากกว่าที่ iPods ทำได้เสียอีก หาก Apple สามารถพัฒนาระบบแนะนำสินค้าให้มีคุณภาพมากขึ้น ก็อาจสามารถทำเงินเพิ่มได้จากการแนะนำขายสินค้าที่ตรงใจผู้บริโภคแต่ละรายไป
เครือข่ายสังคมออนไลน์ในปัจจุบันมีเครื่องมือต่างๆ มากมายที่ผู้ใช้บริการสามารถสร้างคอนเทนต์ได้ด้วยตัวเอง ผลที่ได้คือ ข้อมูลอันมากล้นที่รอคอยการสกัดนำไปใช้ประโยชน์ ผู้ที่จะชนะสงครามเสิร์ชเอ็นจิ้นในยุคหน้าจึงเป็นผู้ที่สามารถนำทรัพยากรเหล่านี้มาปรับปรุงให้บริการของตนนำหน้าคู่แข่ง
จัดการกับข้อมูลมหาศาล
ตลอดระยะเวลาสิบกว่าปีที่ผ่านมา Google ได้แสดงให้พวกเราเห็นว่าการพิมพ์คำค้นหาหรือคีย์เวิร์ด คือวิธีการที่ดีที่สุดในการค้นพบสิ่งที่เราต้องการในโลกออนไลน์ แนวคิดดังกล่าวกลายมาเป็นโมเดลธุรกิจที่สามารถทำเงินให้กับเสิร์ชเอ็นจิ้นใหญ่แห่งนี้ได้ปีละมหาศาล แต่ในยุคที่เครือข่ายสังคมออนไลน์ครองเมืองและผู้ใช้ต่างแบ่งปันข้อมูลอย่างไม่บันยะบันยังผ่านการกด “ไลค์” และ “แชร์” นั้น ได้ช่วยให้แนวคิดเรื่อง Semantic Search ได้รับการจับตาเป็นอย่างมาก และคาดว่าจะมามีผลต่อพฤติกรรมการใช้งานอินเทอร์เน็ตของเรามากขึ้นในปีนี้
Semantic Search คือแนวคิดที่จะปรับปรุงผลการค้นหาให้มีความแม่นยำมากขึ้น โดยอาศัยเทคโนโลยีที่จะเข้ามาช่วยทำความเข้าใจเจตนาของแต่ละบุคคลและ “ความหมายตามบริบท” (Contextual Meaning) ของคำค้นหาที่อาจประกอบไปด้วยหลายองค์ประกอบมายมาย อาทิ เวลาและสถานที่ ความหลากหลายของคำ และคำเหมือน เป็นต้น
แน่นอนว่าสิ่งที่ Semantic Search ต้องการก็คือ ปริมาณข้อมูลมากมายมหาศาล และในปัจจุบันผู้ที่ดูเหมือนจะเก็บขุมทรัพย์ผู้ใช้ไว้มากที่สุดคงหนีไม่พ้น Facebook ที่ได้พยายามเป็นศูนย์กลางข้อมูลบนโลกออนไลน์ของผู้ใช้ทุกอย่าง ไม่ว่าจะเป็นอัลบั้มภาพถ่ายครอบครัวและเพื่อนฝูง สมุดหน้าเหลือง หรือสำนักข่าวบน News Feed แน่นอนว่าเมื่อมีคลังข้อมูลมากขนาดนี้ หากจัดการไม่ดีความยุ่งเหยิงก็บังเกิด ที่ผ่านมา Facebook ตกเป็นเป้าวิจารณ์ว่าไม่สามารถจัดการคอนเทนต์ที่ปรากฏบน News Feed ได้ดีพอ เราจึงได้เห็นภาพถ่ายส่วนตัวของเพื่อนที่เราไม่เจอกันมาเป็นสิบปี หรืออัพเดตสถานะจากใครก็ไม่รู้ที่เราเผลอไปกด “เพิ่มเป็นเพื่อน” ขณะที่เครือข่ายสังคมออนไลน์อื่น อาทิ Twitter, Line หรือ Instagram (ซึ่ง Facebook เป็นเจ้าของ) มีทิศทางที่ชัดเจนกว่าว่าจะให้บริการของตนมีความโดดเด่นในด้านใด เช่น อัพเดตสถานะ สนทนา หรือแบ่งปันภาพถ่าย เป็นต้น
Facebook ได้พยายามแก้ไขข้อด้อยดังกล่าวอย่างเงียบๆ ตลอดทั้งปี 2013 ที่ผ่านมา ด้วยการปรับแต่งอัลกอริธึมของ News Feed ให้แสดงคอนเทนต์ที่ “โดนใจ” ผู้ใช้มากขึ้น กล่าวคือ ข้อมูลที่ Facebook คาดว่าสำคัญต่อผู้ใช้จะปรากฏขึ้นมาเป็นลำดับแรกๆ โดยไม่เรียงลำดับเวลา โดยอาศัยการวิเคราะห์เนื้อหาที่ผู้ใช้สร้างขึ้นจากการ “ไลค์” และ “แชร์” ต่างๆ นั่นเอง การพัฒนาคุณสมบัติเหล่านี้นับเป็นเรื่องที่จำเป็น เพราะนอกจากจะทำให้ผู้ใช้พอใจกับบริการมากขึ้น ก็ยังทำให้การแสดงผลโฆษณามีประสิทธิภาพมากขึ้นเช่นกัน และเพื่อเป็นการตอกย้ำความเป็นผู้นำในด้านนี้ Facebook ยังได้เปิดตัวทีมวิจัยระบบปัญญาประดิษฐ์ไปเมื่อเดือนธันวาคมที่ผ่านมา ยิ่งทำให้น่าติดตามว่าการแสดงผลบน News Feed ของเรานั้นจะเปลี่ยนไปมากน้อยเช่นใด
สำหรับ Facebook แล้ว ข้อมูลมหาศาลไม่เพียงแต่จะมอบความท้าทายในการพัฒนา News Feed และเป็นวัตถุดิบชั้นยอดในการเรียกเก็บค่าโฆษณาเท่านั้น แต่ยังหมายถึงการถ่วงดุลอำนาจกับเสิร์ชเอ็นจิ้นยักษ์ใหญ่อย่าง Google เช่นกัน ที่ผ่านมา Facebook ได้เปิดตัว Graph Search อันเป็นนวัตกรรม Semantic Search ที่จะนำข้อมูลจากฐานผู้ใช้ที่มีอยู่มากมายมาผนวกกับผลที่ได้จากเสิร์ชเอ็นจิ้นภายนอก (ในที่นี้คือ Bing) ยกตัวอย่างเช่น หากเราค้นหาร้านอาหารฝรั่งเศสในกรุงเทพฯ โดยใช้ Google ผลที่ได้ก็อาจจะเป็นเพียงรายการลิงก์ที่จะนำเราไปยังเว็บไซต์ร้านอาหาร หรือกระทู้ต่างๆ แต่หาก Graph Search ของ Facebook พัฒนาสมบูรณ์ ไม่เพียงแต่เราจะได้รายการร้านอาหารอย่างเดียวเท่านั้น แต่เราอาจจะได้รายละเอียดเพิ่มเติมอย่างเช่น เป็นร้านที่เพื่อนของเราเคยไปทานมาแล้ว หรือเป็นร้านที่คนซึ่งมีไลฟ์สไตล์เดียวกับเราแนะนำต่อๆ กันมา เป็นต้น
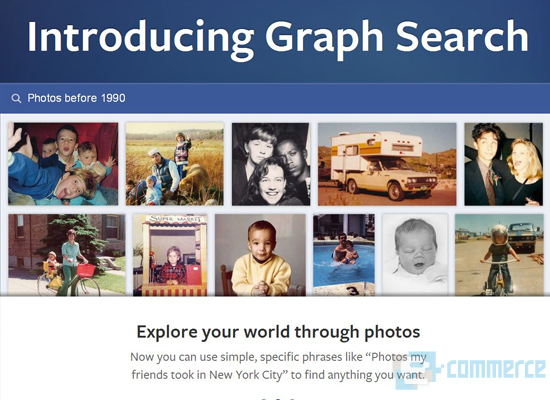
Graph Search จาก Facebook ช่วยให้เราได้ผลการค้นหาที่ตรงใจมากขึ้น
นอกจาก Facebook แล้ว Google เองก็ทราบดีว่าข้อมูลที่มีอยู่มากมายบนโลกออนไลน์คือ ขุมทรัพย์ที่มีค่ามหาศาล จึงได้เปิดตัว Knowledge Graph ที่มีลักษณะเป็นกล่องข้อความแสดงอยู่ทางขวามือ ภายในมีบรรดาข้อมูลพื้นฐานของสิ่งที่เราใส่คีย์เวิร์ดลงไป จึงทำให้ผู้ใช้ได้รับข้อมูลเบื้องต้นของสิ่งที่ต้องการได้ทันทีโดยทีไม่ต้องคลิกไปยังเว็บไซต์อื่นให้วุ่นวาย ยกตัวอย่างเช่น หากเราค้นหาชื่อนักร้องที่ชื่นชอบ ข้อมูลที่ปรากฏภายในกล่องข้อความก็จะประกอบไปด้วย ชื่อจริง ภาพถ่าย ผลงานเพลง รวมทั้งนักร้องคนอื่นที่ผู้คนค้นหา ปรากฏอยู่ในที่เดียว
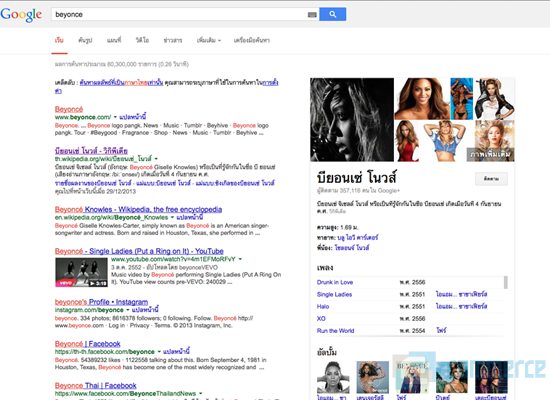
ที่เห็นทางขวามือคือ Knowledge Graph กล่องข้อมูลเบื้องต้นของสิ่งที่ผู้ใช้ค้นห
คุยกับเสิร์ชเอ็นจิ้น!
การใช้คีย์บอร์ดพิมพ์คำค้นหาอาจกลายเป็นพฤติกรรมที่ล้าหลังในอีกไม่กี่ปีข้างหน้าเมื่ออุปกรณ์คอมพิวเตอร์ใหม่ๆ ได้รับการออกแบบมาให้รองรับการสั่งด้วยเสียงเป็นหลัก ยกตัวอย่างเช่น Google Glass, Google Now หรือผู้ช่วยดิจิทัลอย่าง Siri ของ Apple การถือกำเนิดขึ้นของอุปกรณ์ไฮเทคเหล่านี้มีแนวโน้มทำให้เราต้องเปลี่ยนลักษณะการค้นหาจากเดิมที่เป็นคีย์เวิร์ดเป็นคำๆ ไปเป็นรูปแบบประโยคสนทนาทั่วไป อัลกอริธึมในยุคหน้าจึงต้องวิเคราะห์ทั้งคำและประโยคของผู้ค้นหาเพื่อให้ได้ผลลัพธ์ที่แม่นยำ

อีกไม่นานการคุยกับเสิร์ชเอ็นจิ้นผ่านมือถือขณะขับรถคงเป็นพฤติกรรมที่แสนธรรมดาไปเสียแล้ว
อย่างที่กล่าวไป การที่ Apple เข้าซื้อกิจการ Topsy ก็เพื่อต้องการนำความรู้ความสามารถที่ได้ไปพัฒนาระบบแนะนำสินค้าในร้านค้าออนไลน์ของตนให้ตรงตามที่ลูกค้าแต่ละคนต้องการมากขึ้น เพราะฉะนั้น จึงเป็นไปได้ว่าเทคโนโลยีการค้นหาในอนาคตจะมีความสามารถในการคาดเดาสิ่งที่ผู้ใช้ต้องการได้ล่วงหน้ายกตัวอย่างเช่น Google Now ที่สามารถคาดเดาสิ่งที่ผู้ใช้ต้องการจากประวัติการค้นหาที่ผ่านมา และแสดงผลผ่านทางการ์ดต่างๆ เพียงแค่เปิดแอปพลิเคชันเท่านั้น
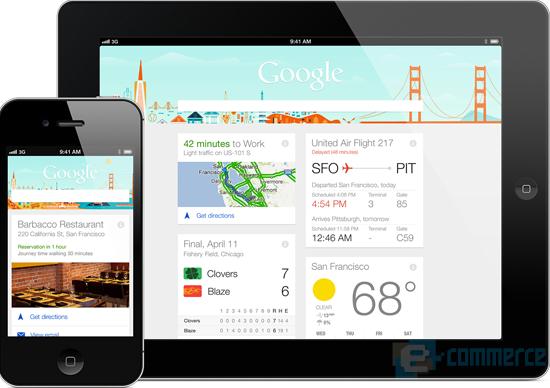
Google Now สามารถคาดเดาสิ่งที่ผู้ใช้ต้องการล่วงหน้าโดยอาศัยประวัติการค้นหาที่แล้วมา
สรุป
ในอดีต เสิร์ชเอ็นจิ้นเป็นเพียงการแสดงหน้าเว็บไซต์ที่มีคำซึ่งตรงกับคีย์เวิร์ดที่เราพิมพ์ลงไป สิ่งที่ได้คือผลการค้นหาที่แม่นยำในระดับหนึ่ง แต่ในปัจจุบันเครือข่ายสังคมออนไลน์ได้เอื้อให้ผู้ใช้สามารถแบ่งปันข้อมูลรายละเอียดต่างๆ ได้อย่างง่ายดายมากขึ้น โลกออนไลน์จึงไม่เพียงแต่จะเต็มไปด้วยข้อมูลที่ผู้ส่งสารถ่ายทอดออกมาเท่านั้น แต่ยังประกอบไปด้วยข้อมูลที่ผู้รับสารสื่อสารกันเองที่กลายมาเป็นคลังข้อมูลขนาดยักษ์รอคอยการนำไปใช้ประโยชน์
ผู้ให้บริการบนโลกออนไลน์ได้ตระหนักถึงศักยภาพของคลังข้อมูลดังกล่าว หลายบริษัทกำลังอยู่ในระหว่างการพัฒนาเครื่องมือและเทคโนโลยีที่จะนำข้อมูลมหาศาลเหล่านั้นมาใช้เพื่อประโยชน์ของผู้บริโภค (และตัวเอง) ไม่ว่าจะเป็นการที่ Facebook พัฒนาอัลกอริธึมให้ News Feed สามารถแสดงคอนเทนท์ที่ตรงใจผู้บริโภคมากขึ้น หรือพัฒนา Graph Search เพื่อให้ได้ผลการค้นหาที่แม่นยำกว่าอาศัยเพียงคีย์เวิร์ด หรือการที่ Google พัฒนา Knowledge Graph ที่เอื้อให้ผู้ใช้ได้รับทราบผลการค้นหาเบื้องต้นได้รวดเร็วขึ้นในหน้าจอเล็กๆ เพียงที่เดียว
ทั้งหมดแสดงให้เห็นแนวโน้มในอนาคตของเสิร์ชเอ็นจิ้นในยุคหน้าที่ไม่เพียงแต่จะแสดงข้อมูลที่ตรงกับคีย์เวิร์ดเท่านั้น แต่ได้อาศัยบริบทที่เกี่ยวข้องในการแสดงผล “ชุด” ของข้อมูลที่มีความเกี่ยวข้องกัน โดยอาศัยระบบที่สามารถคาดเดาความต้องการของผู้ใช้เพื่อเป็นการประหยัดเวลาในการค้นหา (และป้องกันไม่ให้หนีไปใช้บริการของที่อื่น) อีกทั้งยังมีความแม่นยำสูง และถูกปรับแต่งให้เหมาะสมแต่ละบุคคลนั่นเอง
สนับสนุนบทความโดย นิตยสาร E-Commerce ฉบับที่ 182 ฉบับเดือน กุมภาพันธ์ 2557